
pipeline
Restspace enables you to program with its own service components and services on the web. The primitives with which you program are web services, which can be any web service or API on the internet. Restspace also provides you with its own library of web component primitives.
Pipelines are what Restspace gives you to compose these primitives together into more complex services which can then be composed again, etc. A service component is simply a function which takes in an HTTP request and sends back an HTTP response. These two HTTP messages are extremely similar, only differing in what headers are valid. If we viewed a service component as simply a function on an HTTP message returning another HTTP message, we can see they naturally could be formed into pipelines, sending the response from one as a request to the next.
This use of the pipes and filters pattern is a twist to the philosophy of HTTP as a client/server communication mechanism. However it enables a novel and powerful way of working with web services in a pipes and filters style.
Restspace provides a specification language for pipelines. Features of Restspace pipelines include:
- Run in serial or parallel, with concurrency control
- Parameterisation based on the calling url
- Split a message into parts or combine parallel
messages based on JSON, multipart messages or file zip. - Call urls conditionally based on the input
message or previous error state - Subpipelines
- Apply JSON transformations to a message at any
step
These features are rich enough to provide many of the features of a programming language.
A pipeline specification is simply a JSON fragment which is interpreted in a specific way.
Initial Examples
To give you a sense and context of what a pipeline looks like, here are 3 examples and basic explanations of what they do:
HTML Page Template
[
"GET /json/pagedata.json",
"/templates/pagetemplate.html"
]A simple serial pipeline like this is just a list of request specifications for each step.
Here we simply get some JSON data and POST it (POST is the default action) to a template. The output is an HTML page. Restspace services which transform data adopt a convention in a case like this that GET gets the transform specification (the template itself here), PUT writes the transform specification, and POST applies the transform to the POSTed payload.
Write hook
[
"POST /json/records/$*",
"/sendemail"
]When you POST data to this pipeline, the first request POSTs that data on to a path beginning /json/records.
This url for this step uses a url pattern. A pipeline (or most other Restspace services) is associated with a url. The routing system sends all requests to that url and all requests to urls that start with that url to the pipeline. We call the url a base path, e.g. /my-pipeline. When the pipeline is called, the rest of the url after the base path is called the service path e.g. for /my-pipeline/abc/xyz, the service path is /abc/xyz.
Url patterns contain codes or macros which are substituted by elements of another url called the context url. In this case, $* means the service path of the context url, and the context url is just the url of the request that invoked the pipeline.
You can see how this mapping enables you to post to any resource that starts /json/records, e.g. if you POST data to the pipeline (which is on a base path /my-pipeline) on /my-pipeline/mno/pqr, it will post that data on to /json/records/mno/pqr.
After it does that, it will POST to /sendemail which we assume, sends an email as an indication that the data was written.
If a pipeline request fails, the default behaviour is for the pipeline to terminate and return the failure message. Because this pipeline is serial, that means we can be sure the data was written if the email is sent.
Fetch related data
[
"GET /json/order-items/$>0",
[
":$this",
"GET /json/orders/${orderId} :order",
"GET /json/users/${userId} :user"
],
"jsonObject"
]This pipeline fetches an order item then in parallel, fetches the related order and user data, then returns everything as a combined json object.
$>0 is a url pattern which is substituted by the first segment of the service path, so for example if we call this with /my-pipeline/123/456, $>0 is replaced by 123.
This gets the order item data. We then see a sublist which indicates a subpipeline. A subpipeline is generally executed in a different mode from the pipeline which contains it. By default, a subpipeline of a serial pipeline is executed in parallel, and vice versa.
So we see 3 pipeline steps to be executed in parallel. The colon prefixed parts of the step specifications gives a name to the output of the step. The first one is a special case: there is no actual request, we are just giving a name to the data passed in which is passed straight on. The special name $this is relevant later.
The other two requests use the ${<property>} url pattern which is substituted by the value of a property (or property path) from the body of the previous request.
Pipeline Elements
A pipeline is made up of a list of elements. A step can be one of the following:
- Initializer - a directive to configure the pipeline
- Step – a request to a url optionally with a condition, method and/or name (string)
- Subpipeline, which is a nested list of steps – this provides a new pipeline context (list)
- Mode Directive – how the flow in the pipeline reacts to failed and succeeding conditions (string)
- Splitter – creates many messages from one, which all then proceed in parallel down the pipeline (string)
- Joiner – joins all the messages into the pipeline into one message (string)
- TargetHost Directive – specifies a domain to which all site-relative urls refer (string)
- Transformation – a JSON transform (object)
Pipeline Steps
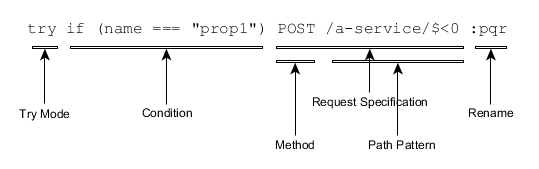
The above illustrates the components of a Pipeline Step.
- Request specification – this contains an optional method (the default without it is POST) and a Url pattern which is an absolute URL or site-relative URL (starts with /) which can contain substitution codes (which all begin with $). Url patterns are described elsewhere.
- Rename – this applies a name to the output message. Generally a joiner will use the name to distinguish parts of the joined payload originating from different messages.
- Condition – an optional test on the input message to apply to determine whether to execute this step. What happens after a success or failure depends on the Pipeline Mode. By default the pipeline continues to the next step in either case.
- Try Mode – indicated by prefixing a 'try' to the Pipeline Step, this indicates that the following pipeline elements are going to be executed dependent on the result of this step. Also, instead of the normal behaviour of an error code resulting in the pipeline immediately terminating, this mode encodes the error into a message payload that the subsequent conditions can test for.
A step can be just a Rename in which case it passes the message unchanged except for renaming it.
Conditions
A condition on a step in a pipeline tests a message before executing a step. In a parallel subpipeline, if the condition fails, the message copy for that step does not continue down the pipeline. In a serial subpipeline, failure or success results in an action specified by the current mode.
Where there is a subpipeline in a pipeline, the condition on the first pipeline step in the pipeline determines whether the pipeline is executed at all, rather than just whether that conditional step is executed.
Conditions are essentially the head of a Javascript if expression without the body (the body is the request specification). There are certain limitations on the Javascript you can use (notably, no anonymous functions). See bcx-expression-evaluator docs for the details of this. You have a range of variables preset relating to the current request (or the original request to the pipeline):
- name: the name of the message
- mime: the Content-Type (mime type) of the message
- isJson: the mime is a JSON type mime
- isText: the mime is a text type mime
- isBinary: the mime is neither text nor JSON
- status: the status code of the message
- ok: if the message succeeded (0 or 200 status)
- method: the method of the original request
- subpath: for a pipeline which handles calls to all its subpaths, the subpath as an array of path elements
- header(key): the header value whose key is given
- body(): the JSON conversion of the message body, given that the message does not have a stream body. You can ensure this by processing the message with
/lib/destreambefore this test. - query(): an object representing the query fields of the message, the key being the query argument key, and the value being the query argument value.
Try mode
A pipeline step (and a pipeline) can operate in try mode. This sets the pipeline up so as to execute conditions against the result of the pipeline step. A step is run in try mode if prefixed with try. A try mode step does not terminate the pipeline if the request returns an error status as it usually would. Instead an error response is converted into a message with 200 status and an application/json body that looks like this:
{
"_errorStatus": <error status code number>,
"_errorMessage": <error message string>
}The pipeline in try mode operates as if it were serial next end mode. This means the first step or subpipeline with a succeeding condition is the only one which is executed in the rest of the pipeline.
When the try mode pipeline has a subpipeline, its default mode is not parallel as it would normally be but serial. This supports subpipelines representing chains of conditional actions.
When the try mode pipeline ends, if the message was converted from a failure to a success with error data, it is now converted back to a failed message before being passed back to any parent pipeline. This means the conditional steps in the pipeline act like exception handlers, and if none is triggered, the failure is treated as normal.
As an example:
[
"try GET /json/data0",
[ "if (status === 404) GET /json/default", "/transform/transf-default" ]
]This pipeline attempts to get JSON from /json/data0, but if there is no data there (404 error), it will get JSON from /json/default and pass it through the transf-default transform.
Pipeline modes
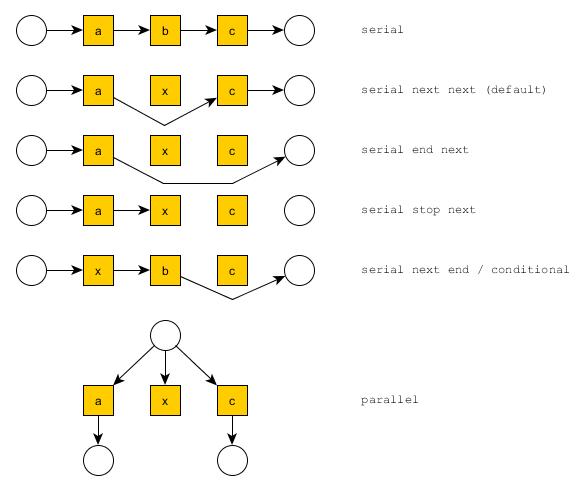
A pipeline can also manage more complex graphs of services, running services in parallel, splitting compound messages, processing the parts and merging them. A pipeline can have subpipelines which are configured by creating a subarray in the array representing a pipeline. Each pipeline or subpipeline is a context in which execution proceeds in a given mode. A mode can be parallel or serial, and in a serial mode you can specify how the pipeline behaves when encountering a step whose condition succeeds or fails.
The possible modes are shown below with their mode specification. The x indicates a step whose condition failed.
The mode specification follows the pattern <parallel or serial or conditional> <fail behaviour> <succeed behaviour>.
The top level pipeline is serial next next by default. A subpipeline of any serial pipeline is parallel by default. A subpipeline of any parallel pipeline is serial next next by default.
The serial mode operates as already described, each message that enters the subpubipeline is sent to the url in the first step, the response(s) sent to the url in the second step, and the final response(s) returned as the subpipeline's output.
When starting parallel mode, each message in the pipeline is copied once for each step in the parallel subpipeline and passed to those steps in parallel. Messages with streams in their bodies have the streams forked for each copy. The messages output from the subpipeline continue along the parent pipeline in parallel. When multiple messages are being processed by the pipeline at once, each one is labelled with a name (described in more detail later). In this case, the default name is the zero based position index of the step in the parallel subpipeline. If the step has a rename specified, this name is used instead.
Tee and TeeWait modes
These modes specify that instead of the next step after the pipeline receiving the output of the pipeline, it receives the input to the pipeline unchanged. You could view that as the pipeline branching off the main flow but not reconnecting to it. With tee, the main pipeline does not wait for the tee mode subpipeline to finish, it continues immediately. teeWait does wait for the tee mode subpipeline.
Pipeline directives: splitters and joiners
Pipelines can also include pipeline operators. These fall into the categories of split and merge operators. These specify a way of splitting a message which in some way has parts into multiple messages for each of those parts, whilst merge operators specify a way of combining all the messages in the pipeline into one. Split operators can be used at any point in a pipeline: the resulting messages are all run through the subsequent pipeline elements in parallel. Split operators assign a name to each part (it sets the header Content-Disposition: form-data; name=<name>) and merge operators use the name when combining the parts.
Split operators are:
split: takes a 'multipart/form-data' message and splits it into a message for each part, giving each message the fieldname as its name.unzip: takes an 'application/zip' message and unzips it into a message for each file, giving each message it's path in the zipped structure as its name.jsonSplit: takes a JSON message and if it is a list or object splits into into a message for each list item or property, named with the list index or property name.
Merge operators are:
multipart: a 'multipart/form-data' formatted message is created. In this case each message's data is combined as a field value whose name is the name of the message. Streams are preserved by creating a new stream out of the streams of the parts.zip: an 'application/zip' message is created. Each consituent message is added to the zip archive with its name as the filename and its data as the file. Streaming is preserved by combining streams.jsonObject: creates an 'application/json' message for a JSON object created by adding a property for each message whose key is the message's name and whose value is the JSON object in the message for JSON data, the text as a string for text data, or the binary data as a base 64 string for binary data.
Transformations
A transformation is an object in the JSON specification. It defines a JSON transformation to be applied to the body of the message. Essentially it outputs the JSON object given with every string-valued property interpreted as an expression based on the input message JSON. The expression is Javascript with some additions and some limitations, notably no literal functions are allowed. See Transform service for more details.
Subpipelines
A subpipeline indicates a context in which a pipeline mode operates. By default, the top level pipelines is serial next next mode. The subpipeline of any serial pipeline is parallel mode. The subpipeline of a parallel pipeline is serial next next mode.
If there's a condition on the first element of a subpipeline, the entire pipeline will not be executed if the condition fails.
Initializer directives
- The
targetHostdirective has one argument, a domain with a scheme, which indicates the default host for the pipeline. All site-relative urls (i.e. beginning with /) are sent to this domain, and any Authorization header sent with the initial request to the pipeline is forwarded to this domain. - The
concurrencydirective has one argument, a number which specifies the maximum number of requests the pipeline will run in parallel. The default limit is 12. Setting the limit to zero removes any concurrency limiting.
Using different HTTP methods
If you call a pipeline with any method except OPTIONS, the pipeline will run and the method called with can be accessed by using the $METHOD macro for the method of any of the requests in the pipeline definition.
When called with OPTIONS the pipeline does not run, it returns immediately.
Efficiency, streaming and async
The pipeline implementation is designed to maximise the efficiency of all operations. Operations following on from operations being run in parallel are started as soon as the previous operation returns, rather than waiting for all previous parallel elements to complete. Data is held as streams (which are forked if necessary) for as long as possible, so that data can start being returned from a pipeline as soon as possible, before all pipeline operations have completed.